Text Retrieval and Search Engines(1)
此文内容整理自Coursera课程文本检索与搜索引擎(Text Retrieval and Search Engines)。
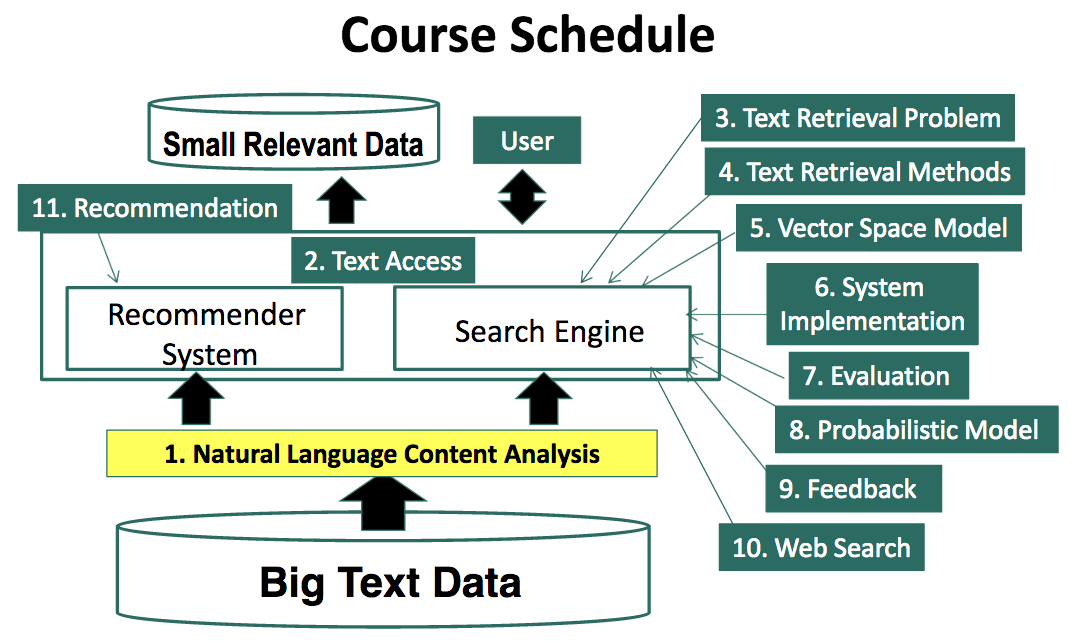
课程结构
术语表
- Text Retrieval(TR):文本检索
- Information Retrieval(IR):信息检索
- Natural Language Processing(NLP):自然语言处理
- Information Need:信息需求
- Document:文档
- Query:查询
- Relevance:相关度
- Similarity:相似度
- Ranking Function:排序函数
- Vector Space Model(VSM):向量空间模型
- Term:关键词(文档中的基本概念),可以是词、短语或ngram等
- Bag of Words(BOW):词袋
- Bit Vector:位向量
- Dot Product:点积
1、文本检索基本概念
第一部分将涵盖上图中1-5部分的内容。
1.1 自然语言内容的分析
这无疑是处理任何文本数据的第一步,本节包含三个小主题:
- 什么是NLP?
- NLP领域研究的现状
- NLP与文本检索
1.1.1 什么是NLP?
来看一个NLP的简单例子:
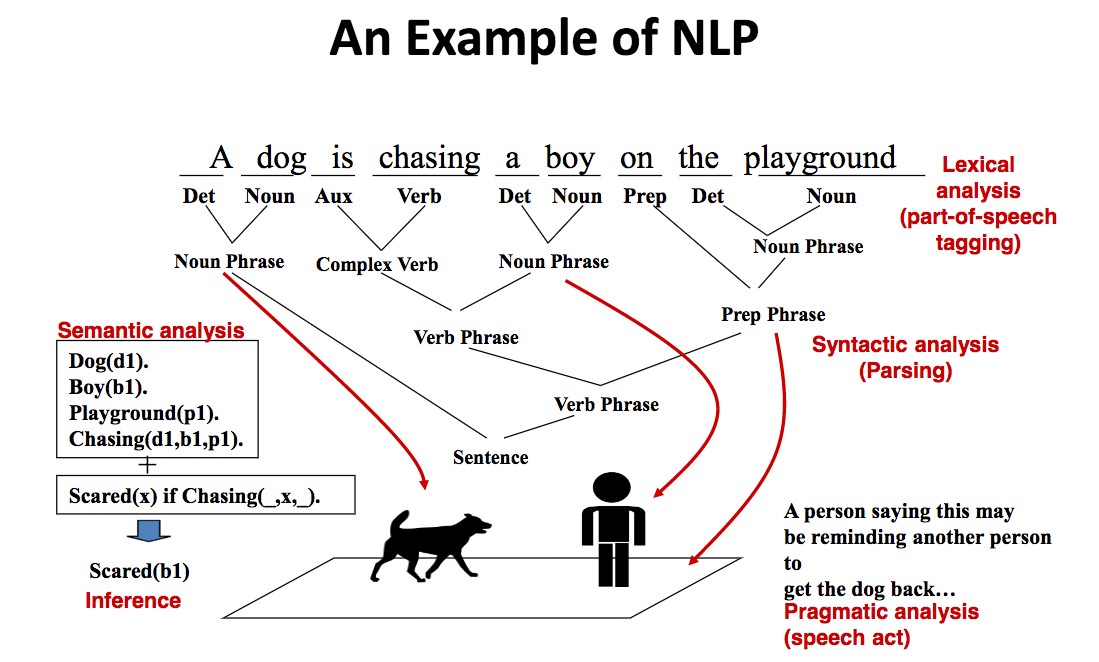
如果想让计算机理解这个句子,需要哪些步骤呢?类似于人类的理解过程,首先需要知道它包含哪些词,以及各个词的词性。这个过程称为词法分析(Lexical analysis)或词性标注(Part-of-speech tagging)。
接下来需要了解句子的语法结构,即这些词如何构成更复杂的语法结构。如A和dog构成名词短语,on、the及playground构成介词短语等等。这个过程称为语法分析(Syntactic analysis)。
了解了句子的词法结构和语法结构,计算机仍不足以了解句子的意义。这时需要的是语义分析(Semantic analysis)。对计算机来说,需要将词和短语这样的成分对应到某些symbol,同时还要有symbol之间的关系,比如上图中的Chasing就是这样一种关系。更进一步,在关系之上,我们还可以进行推理(Inference),比如我们有一条规则:如果某实体被狗追,那么该实体会害怕。在此规则下,我们可以推理出一个结论:the boy is scared。
另外还可以考虑,一个人为何说出这样一句话?ta的意图是什么?一种可能是,ta在提醒另一个人把狗牵回来。这个过程称为Pragmatic analysis,即分析“语言行为“本身。
计算机要理解一个如此简单的句子都需要很繁琐的过程。人类理解起来要容易得多,这是因为人的大脑早已有了庞大的”知识“库,而计算机则需要从头学起。
直觉上,人类学习语言并非如洛克的”白板论”那样,一个人对于语言的理解应当有相当的部分来自于遗传。总之,对于可怜的计算机而言,NLP是很难的。
1.1.2 NLP是很难的
”自然语言“当然是为人类的有效沟通而设计,其结果是:我们会大量的”常识“内容,并假设听者或读者是能够理解的;语言中存在大量的歧义(ambiguity),我们假设听者或读者能够仔细理解之。
当一个人缺乏常识,与ta沟通起来会感觉困难。对NLP来说,以Siri之类的应用为例,我们的感觉不是与它很难沟通,而是完全无法沟通。当一个人说的话有歧义,人类也会觉得理解起来有困难,拿不准其准确含义,遑论计算机了。所以,常识的缺乏和歧义使得NLP格外困难。
歧义的常见情况有:
- 词的歧义:不同词性;多义词;
- 语法结构的歧义:修饰语与被修饰语的不同结合;介词短语附着(PP Attachment),”A man saw a boy with a telescope;
- 首语重复(Anaphora)解析:John persuaded Bill to buy a TV for himself;
- 预先假定(Presupposition):“He has quit smoking”暗示他曾吸过烟。
1.1.3 NLP研究现状
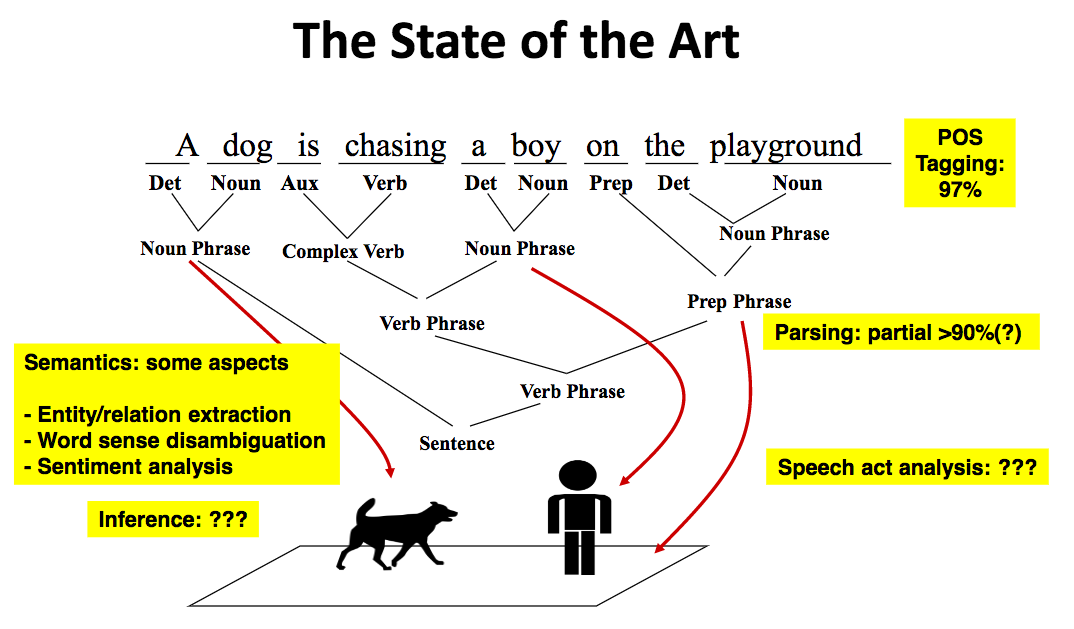
词性标注准确率较高;语法解析层面,部分解析(Partial Parsing,即句子的一部分,如短语级别)达到90%以上。
语义解析的进展则相当不好。不过在某些特定应用上取得了一些进展,如实体识别、关系提取、情感分析。
推理和语言行为方面的表现则是更差。
值得一提的是,尽管说词性标注和部分解析的准确率已经达到较高的程度,但这些评测都是基于特定的测试数据集,此类测试集常常是新闻类数据,这会导致一定的偏差。因此相应的算法应用到不同领域中可能未必有同样好的效果。
1.1.4 NLP与文本检索
文本检索通常涉及大量而广泛的文本,如果希望其中的NLP技术是健壮和高效的,那么目前来看只能采用浅层的NLP。文本的词袋(Bag of Words)表示是最简单的一种,它无疑丢弃了文本的大量信息,但对于大部分(不是全部)搜索任务而言却是够用的。
某些文本检索技术可以自然地解决NLP问题,如语义消歧。
但是,对于复杂的搜索任务,更深层的NLP技术仍是必需的,比如知识图谱(Knowledge Graph)。
1.2 文本访问
一个文本信息系统该如何让用户访问到他们关心的(或相关的,relevant)数据?这里主要考虑两种模式。
- Pull模式(搜索引擎):由用户发起。用户在系统中根据特定的需求开始查询,并浏览相应的结果。此时的需求往往是临时性的,比如查询某个术语、某个作者或一类商品的信息。这种情形下,系统很难预知用户的需求,因此Pull模式较为适合。
- Push模式(推荐系统):由系统发起。如果用户有某种较固定的需求,而且系统对用户比较了解,那么系统可以主动向用户push信息。比如Pocket app在用户使用一段时间后,可以向用户推荐其感兴趣的文章。
在pull模式下,也存在两种不同的方式:
- Querying:用户对自己的需求比较清楚,知道该如何查询。比如当我们知道书名或作者名时,可以直接查询。
- Browsing:用户对需求不甚清楚,希望先在系统中漫游一番。当我们遇到某书店的打折信息,满200减100,但暂时并没有特定要买的书,这时往往从分类或主题开始浏览。
尽管说Browsing属于pull模式,但仔细想想,当用户不太清楚想要什么时,不正是推荐系统发挥作用的地方吗?
1.3 TR中的问题
本节包含三个小主题:
- 什么是文本检索?
- 文本检索 vs. 数据库检索
- 文档选择(Selection) vs. 文档排序(Ranking)
1.3.1 什么是文本检索?
对于使用过搜索引擎的人来说,这甚至算不上是一个问题:)
系统已收集大量(具体的量级视具体问题而定)文档。用户发起查询,表达自己的信息需求(Information Need)。系统返回相关文档给用户。这就是high level的文本检索过程。
文本检索也被称为信息检索(Information Retrieval,IR),但实际上IR的范围更广,因为其数据可能是非文本的。文本检索在业界被称为“搜索技术”。
1.3.2 文本检索 vs. 数据库检索
这里将两者简称为TR和DR,并从不同的角度来看:
- 信息:TR是非结构化的、模糊的;DR是结构化的、具有良好语义的;
- 查询:TR是模糊的、不完整的;DR是具有良好语义的、完整的;
- 返回结果:TR是相关的文档,DR是匹配的记录;
- TR是基于经验的,不能以数学的方式精确判断一直方法的好坏,因此需要借助于用户的介入以评测方法的表现。比如通过用户对于查询结果的后续操作来判断其好坏。
下图是TR的正式定义:

R(q)是一次用户查询的相关文档构成的集合,但一般情况下,它是不可知的,同时也依赖于具体的用户。在此前提下,我们的任务是计算它的近似值。
1.3.3 文档选择 vs. 文档排序
上述任务的两种策略是:
- 文档选择:通过某个函数或二元分类器来确定一个文档是否属于目标集合。对于
C中的每一个文档,它的结果只能是属于或不属于。这里的结果是绝对相关度(absolute relevance)。 - 文档排序:选择某个相关度度量函数,对每个文档判断它在多大程度上与当前用户查询是相关的。这里的结果是相对相关度(relative relevance)。
文档选择必须要严格确定出,一个文档是否是相关的;而文档排序则只需要给出相对的相关对,由用户来决定阈值。现实中,后者也确实更可取的方法。
文档选择法存在固有的问题。其分类器很难达到特别准确的程度,要么过于严格而返回过少的文档,要么过于宽松而返回过多的文档。另一方面,即使它是准确的,所返回的”相关文档“的相关度理应是不同的,而分类器没办法确定出来。
文档排序法的依据来自于概率排序原理(Probability ranking principle),即在如下两个假设下,按文档对于查询的相关度降序排列的列表是最佳策略:
- 文档对于用户的价值(utility)相互之间是不相关的
- 用户会顺序浏览结果
实际上,这两个假设都不一定为真。比如,如果两个文档内容接近,那么用户看过一个后,对于第二个就没有太大兴趣了;用户会跳过部分文档。这两种情况在使用Google之类的搜索引擎时都会遇到。
1.4 文本检索方法
文本检索的定义可见于1.3.2中的图片。简言之,我们需要找到一个合适的排序函数(ranking function)。当前常见的检索模型有:
- 基于相似度(similarity)的模型:Vector space model
- 概率模型:经典概率模型;Language model;Divergence-from-randomness模型
- Probabilistic inference model
- Axiomatic model
本课程主要涉及向量空间模型(VSM)和语言模型(Language model)。有趣的是,尽管上述诸方法的思路颇不相同,但其最终的模型形式却是很相似的。
那么,哪一种模型是最好的?答案是,在优化之后,下面几种模型的表现同样好:
- Pivoted length normalization
- BM25
- Query likelihood
- PL2
BM25是其中最流行。这些模型涉及到的重要概念有:词袋表示、TF、DF和文档长度。
1.5 向量空间模型
VSM是基于相似度的一种模型。所谓基于相似度,是指它以文档和查询之间的相似度来度量相关度。
为计算相似度,我们把文档和查询都表示为向量空间中的向量,如下图所示:
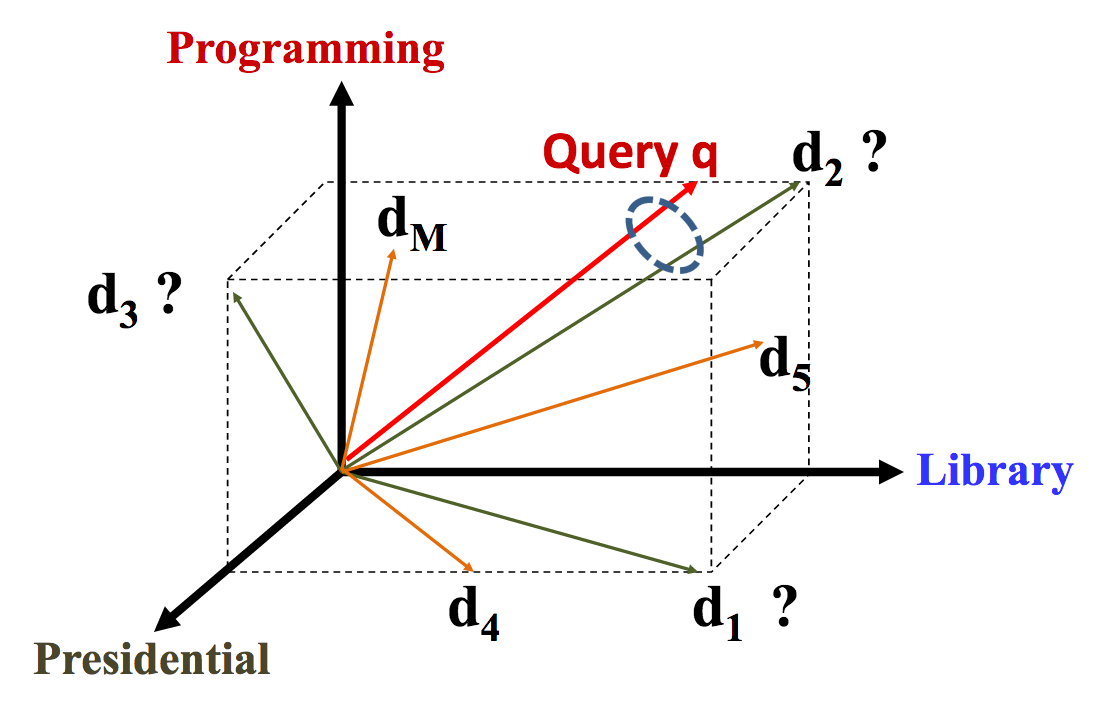
文档d1表示为Library和Presidential两个关键词(term),d2表示为Programming和Library两个term(很可能,这里的Library是指编程中的”库“),而查询q看起来与d2最相似,那么按VSM模型,与该查询相关度最高的文档是d2。
下面给出VSM更正式的定义。VSM是一个框架:
- 将文档和查询表示为term vector
- Term:关键词(文档中的基本概念),可以是词、短语或ngram
- 每个term定义为一个维度
- N个term就定义了一个N维空间
- 查询向量:q = (x1, …, xN), xi ∈ R,这里的xi表示查询在相应维度上的权重(weight)
- 文档向量:d = (y1, …, yN), yi ∈ R,这里的yi表示文档在相应维度上的权重(weight)
- 相关度relevance(q, d)转化为similarity(q, d) = f(q, d)
之所以说VSM是一个框架,是因为这里实际上没有给出任何与具体实现相关的细节。要找到这里的f我们还需要考虑:
- 如何定义或选择关键词?
- 它们需要是正交的(orthogonal)
- 如何为查询和文档向量设置合适的权重?
- 如何度量相似度?
1.6 VSM的最简单实现
VSM的最简单实现是位向量(Bit Vector),即用一个布尔值表示一个term是否出现在了文档中。如果termwi未出现,那么yi = 0,否则yi = 1。而查询也以同样的方式表示。
这种方式的特点之一是,它忽略了一个term在文档中出现的具体次数。另外,当文档集较大(一般都是如此)时,向量维度变得较高,从而使得文档和查询的向量变得很稀疏,即出现大量的0。
这样,文档与查询的相似度可表示为两者向量的点积(Dot Product):
$$Sim(q, d) = q.d = \sum_{i=1}^{N}x_i y_i$$

在这个例子中,V表示文档集中所有term构成的”词汇表“。然后我们列出查询与文档的位向量,然后计算其点积。从结果来看,d2的相似度高于d1。看起来还蛮合理的,这就是我们”最简单的VSM“,它可以总结为:BOW + Bit Vector + Dot Product,编程实现足够简单,只要一个类似于jieba之类的分词工具即可。
那么这里点积的结果作何解释呢?点积的计算结果恰好表示了,同时出现在文档和查询中的term的数量。虽然它有时比较合理,但也会产生一些问题。比如,它只计数共同出现的term数量,数量相同的就没法区分了,也就是说对所有term一视同仁,这与我们的直觉不符,因为某些term应该是更重要的,而像the、about这样的term则不能对相似度提供什么帮助。
后续的课程会介绍不这么简单的VSM:)