Text Retrieval and Search Engines(2)
此文内容整理自Coursera课程文本检索与搜索引擎(Text Retrieval and Search Engines)。Part 1笔记在此
这一部分将更详细地了解VSM,考虑它的不同优化思路,以及借助于倒排索引实现信息检索系统(即搜索引擎)。
主要概念:
- 关键词词频(Term Frequency,TF)
- 文档频率(Document Frequency,DF)与逆向文档频率(Inverse DF, IDF)
- TF transformation
- Pivoted length normalization
- BM25
- 倒排索引(Inverted Index)与posting
- Binary coding,unary coding,gamma-coding和d-gap
- Zipf法则
在Part 1中介绍了”最简单的VSM“(以下简称SVSM),看下图,考虑该模型是否存在问题?

三个文档的相似度计算结果相同,但直觉上,它们应当是有差别的,比如:
- d4匹配到了更多关键词,应获得更高的相似度
- d2的匹配关键词中有一个是about,d3中则有presidential,d3应该与查询更相似
出现这两个问题,是因为我们使用了词袋模型和位向量,首先词频被忽略,这样高频词对相似度的贡献被忽略,接着关键词之间也被同等看待,原本贡献更高的词也泯然众“词”矣。要改进模型,可以从这两方面入手。
先把词频(TF)考虑进去,得到如下的向量表示法:
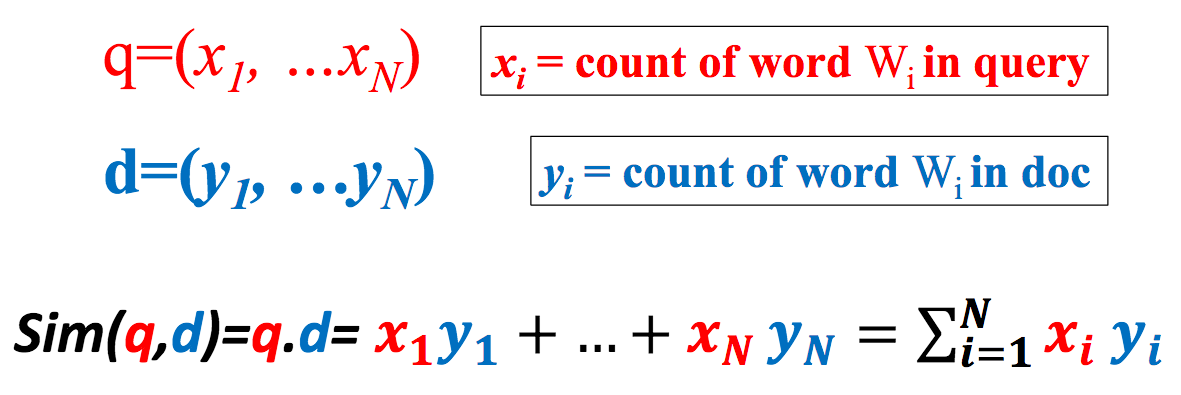
这个新的相似度计算方式可以如何解释?它是否解决了上面的两个问题?
计入词频后,高频词相比于低频词对相似度的贡献会更大,这符合我们的直觉。因为一个文档内,词的频率越高,它就更可能作为该文档的“主题”,而如果一个词频率太低,说不定只是凑巧“混”进了文档而已。
现在重新计算上面的三个文档,会发现f(q, d2) = 3,f(q, d3) = 3,f(q, d4) = 4,它的相似度确实比d2和d3高了,而。这样我们解决了第一个问题,但第二个问题依然存在。
如何给不同的词赋予不同的权重呢?为什么我们会认为presidential要比about重要呢?大致可以这样理解,对于about或the这样的词,它们有很高的频率出现在各种不同主题的文档中,那么查询和文档同时出现这样的词——我们不会感到意外。可以说它们携带的信息很少,不足以区分不同的文档。但presidential就很不一样,介绍信息检索的文章(本文除外)很少会出现。
about这样的词,常常被称为停用词(Stopword)。我们可以考虑用某种方法来“惩罚”停用词。不过首先的问题是,如何确定哪些词属于停用词?可以统计整个文档集的所有词,如果一个词出现在了很高比例的文档中(如80%),那么它很可能是停用词。另一方面,对于像presidential这样的词,我们考虑“奖励”它,因为它们可以更好地区分文档。实现这里惩罚和奖励的常见方法是逆向文档频率(IDF)。标准的IDF实现如下:
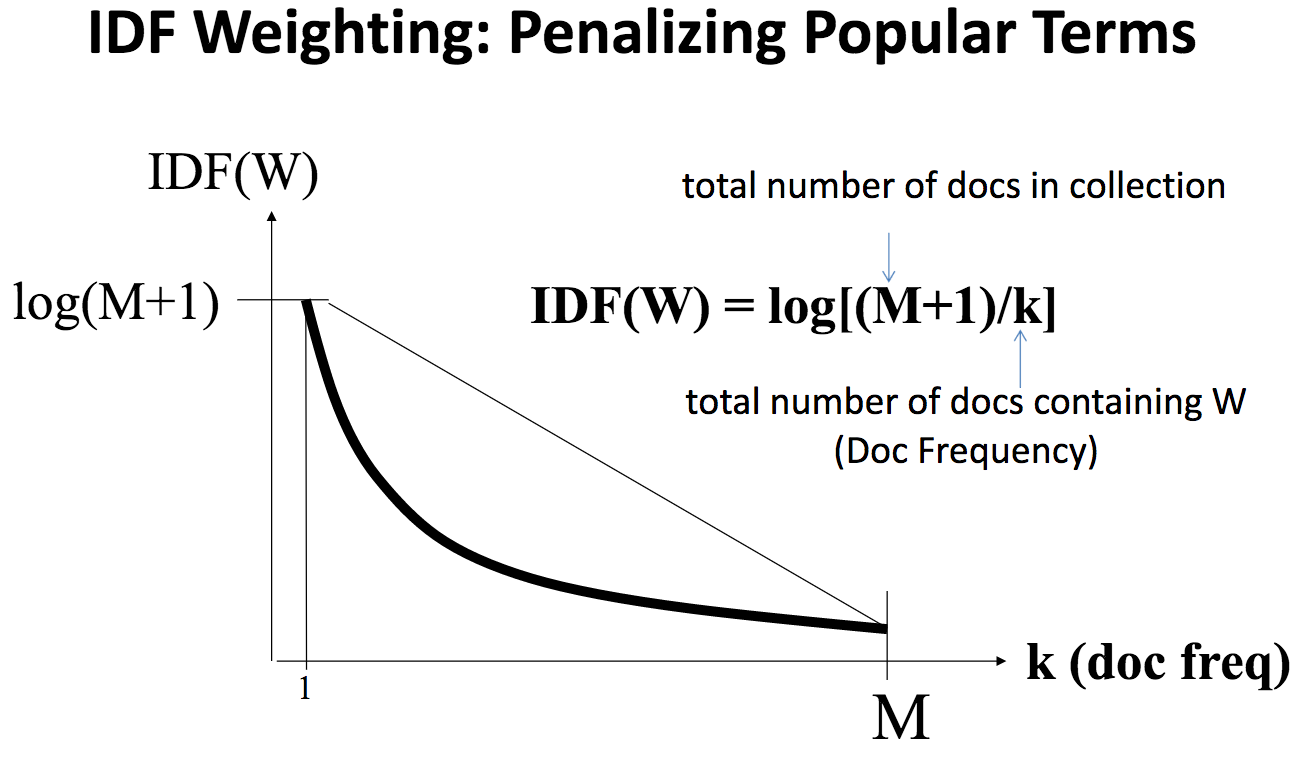
M是文档集中的文档数量,k是包含词W的文档总数,即DF,取到数后就成了IDF。通过函数图像(曲线)可知,一个词出现在越多的文档中,其IDF越低,即得到了越多的惩罚,反之出现在越少的文档中,则会得到奖励。
当k很小时,IDF值很大,也就是说如果一个词只出现在了少数几个文档中,那么他们就会有很高的权重。当k逐渐增大时,IDF下降得很快,直到越过中间的转折点后,IDF就变得相当小,此时该词对于相似度而言就不甚重要了。对于about这样的词,k可能是接近于M的,它的IDF值接近于0。
引入IDF后,文档的向量公式变为:
d = (y1, ⋯, yN,yi = c(Wi, d) * IDF(Wi)
这时再计算的话,d3的相似度就高于d2了,这样就解决了问题2。然而新的问题又出现了,看下图,d5的相似度好像有点过高了,如何解决呢:
